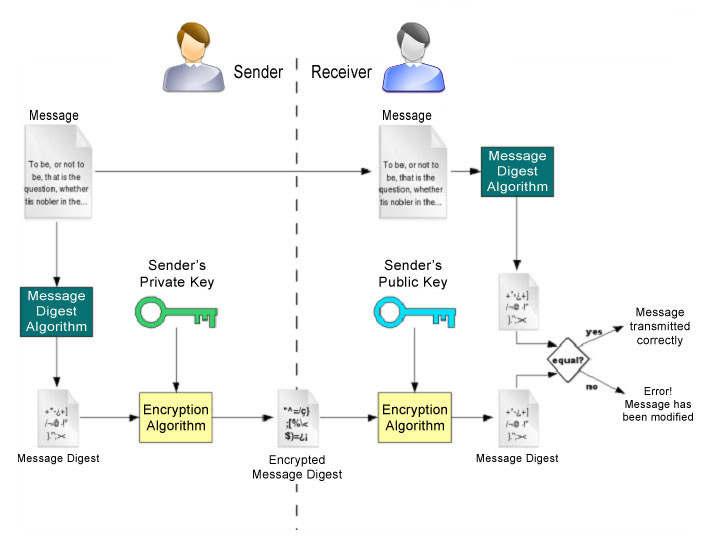
-示例 XACML 實現
XACML 旨在支持授權,而不是身份驗證。
XACML 代表“可擴展訪問控制標記語言”。該標准定義了一種聲明性細粒度、基於屬性的訪問控制策略語言、架構和處理模型,描述瞭如何根據策略中定義的規則評估訪問請求。
-資料來源:維基百科
縮寫 學期 描述
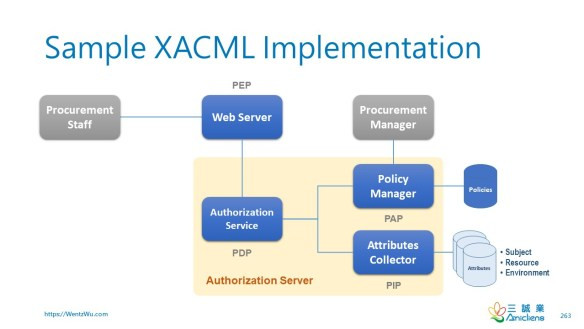
PAP 政策管理點 管理訪問授權策略的點
PDP 政策決策點 在發布訪問決定之前根據授權策略評估訪問請求的點
PEP 政策執行點 攔截用戶對資源的訪問請求,向PDP發出決策請求以獲得訪問決策
(即對資源的訪問被批准或拒絕),並根據收到的決策採取行動的點
PIP 政策信息點 充當屬性值來源的系統實體(即資源、主題、環境)
PRP 策略檢索點 XACML 訪問授權策略的存儲點,通常是數據庫或文件系統。
-資料來源:維基百科
端口敲門和單包授權 (Port Knocking and Single Packet Authorization
:SPA)
802.1X是為認證而設計的,用於網絡訪問控制,而端口敲門是傳輸層的一種認證機制。連接嘗試的正確順序可以被視為身份驗證的秘密。只有當端口敲門序列正確時,防火牆才會動態地允許連接。
在 計算機聯網, 端口碰撞 是從外部打開方法 的端口 上的 防火牆 通過產生一組預先指定關閉的端口的連接嘗試。一旦接收到正確的連接嘗試序列,防火牆規則就會動態修改以允許發送連接嘗試的主機通過特定端口進行連接。存在一種稱為單包授權 (SPA) 的變體 ,其中只需要一次“敲門”,由加密 包組成 。
資料來源:維基百科
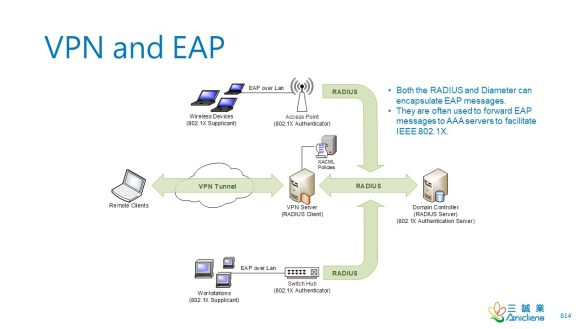
PKI 和 802.1X
公鑰基礎設施 (PKI) 和 802.1X 通常用於在 VPN、LAN 或無線網絡環境中進行身份驗證。
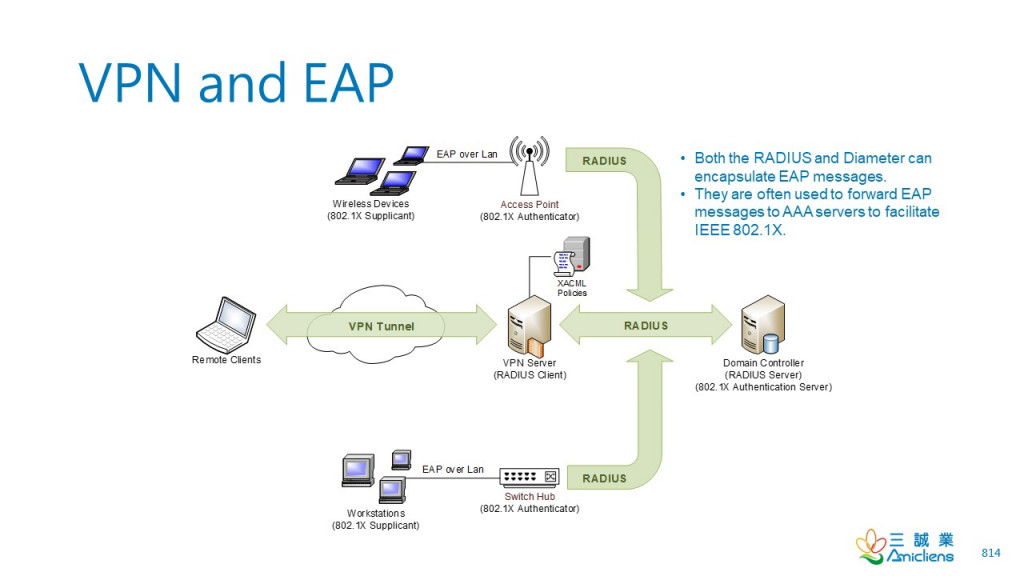
-VPN 和 EAP
參考
. 敲端口
資料來源: Wentz Wu QOTD-20210910
PS:此文章經過作者同意刊登 並且授權可以翻譯成中文